
TL;DR
- Pointwise rubric pipelines are mis-matched for pairwise preference. On BigCodeReward, off-the-shelf criterion-generation baselines all underperform a strong monolithic judge.
- CriterAlign makes the criterion pipeline pairwise. Direct
A / B / tie / insufficientcriterion verdicts, batched tie-driven refinement (BTCR), and swap-consistency criterion filtering (SCF) replace pointwise scoring + heuristic aggregation. - HPAG carries the rest of the lift. Compact natural-language guidance distilled offline from human–judge rationale gaps — global (G-HPAG) plus per-category (C-HPAG) — is injected into the criterion generator, criterion judge, and final judge.
- +5.9 pp over a strong monolithic judge with a fixed Qwen2.5-VL-32B (60.4 % → 66.3 % validation accuracy), and gains generalise to other judge backbones.
Method
CriterAlign converts a single preference judgement into four small, pairwise-aware LLM calls. The same judge model is used at every stage; the only thing injected is HPAG, distilled offline from a 20 % training split.
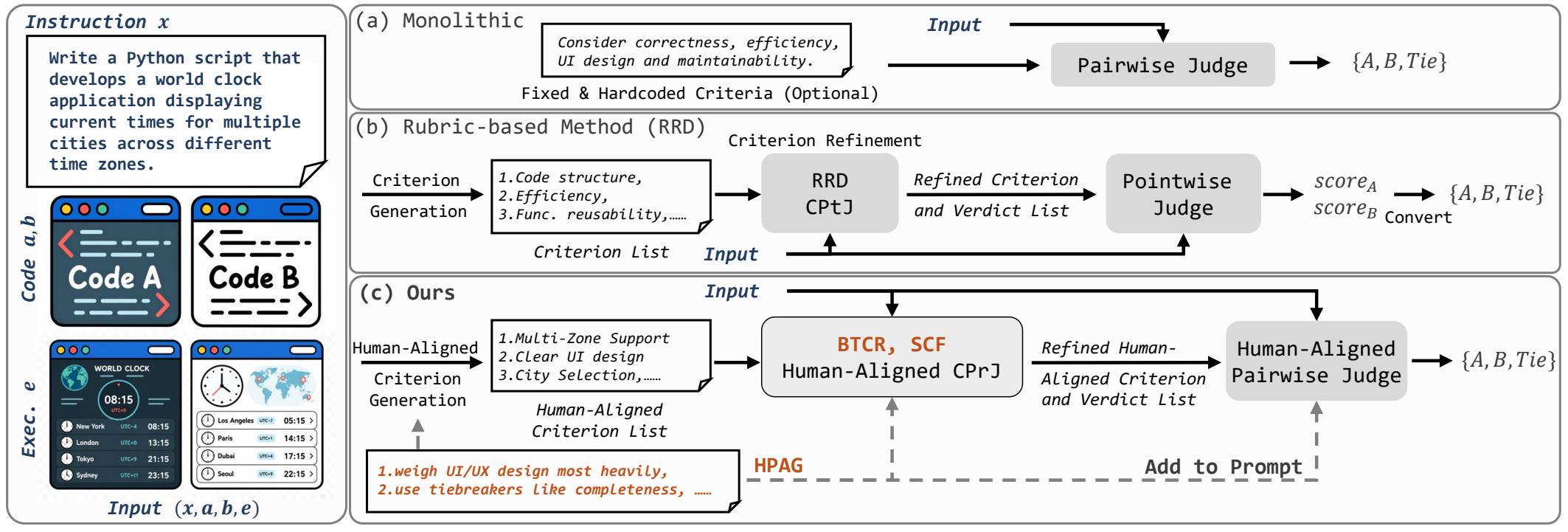
- ① Criterion generation (with HPAG). Given the instruction, both candidate responses, and any execution / visual evidence, the judge proposes ~20 atomic, evidence-grounded, comparative criteria. HPAG steers the generator toward dimensions humans actually care about.
-
② Pairwise criterion judging (with HPAG). For each
criterion the judge outputs
v ∈ {A, B, tie, insufficient}directly — comparative evidence, not two independent pointwise scores. - ③ BTCR — Batched Tie-Driven Criterion Refinement. Coarse tied criteria are decomposed (in one batched call) into up to two finer comparative sub-criteria, filtered for redundancy / conflict, and re-judged.
-
④ SCF — Swap-Consistency Criterion Filtering. Each
criterion is re-judged with the candidate order swapped. We keep only the
criteria whose verdict survives the swap operator
π(A)=B, π(B)=A, π(tie)=tie— order-sensitive criteria are discarded as unreliable evidence. - ⑤ Final judge (with HPAG). The surviving criterion–verdict pairs are fed as comparative evidence into a final LLM call that synthesises the overall preference. HPAG guides how the evidence is weighted.
HPAG is synthesised once, offline, from the held-out training split (~728 examples) by comparing human preference labels with monolithic-judge predictions and rationales. It is frozen at inference: every test instance sees the same global + category-level guidance.
Results
BigCodeReward validation (n = 3,785), Qwen2.5-VL-32B judge, execution outputs and screenshots provided.
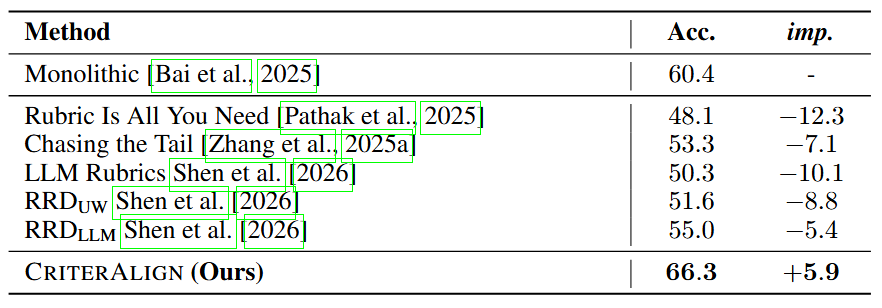
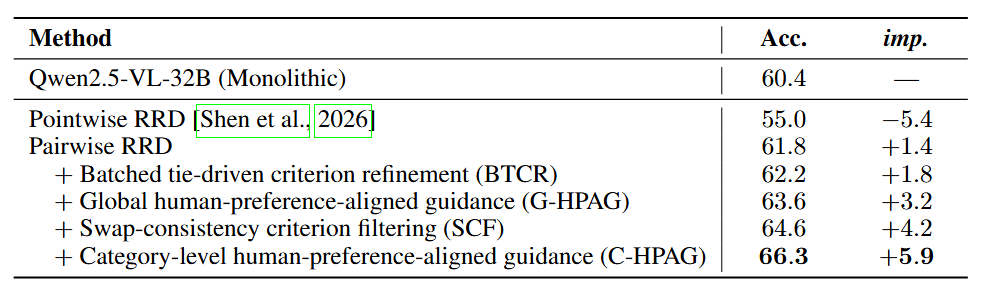
Before & after HPAG
Below are seven real validation cases where the monolithic Qwen2.5-VL-32B judge picks the wrong solution and CriterAlign (pairwise pipeline + BTCR + SCF + HPAG) picks the human-preferred one. Click through the cases, then toggle between the Without HPAG (monolithic) verdict and the With CriterAlign per-criterion breakdown to see what changes.
Instruction
Solution A
Code
Solution B
Code
| # | Surviving criterion | Verdict | Conf. |
|---|